A500 Detailed Description
A500 & A700 FOREWORD

Taking the award winning performance of the Buchardt S400 as a starting point for further improvement, the next step in performance evolution is to take control of the rest of the reproduction stages. This leads to the development of the Buchardt A500 and A700 digital wireless DSP controlled active speakers. Please allow us to clarify in detail why we spent over three years of extensive development to achieve our goals.
ACOUSTIC FOUNDATION
For the A500 and A700, we used the foundation and award-winning acoustic configuration known from the Buchardt S400 and looked at it with fresh eyes. What can be improved even further? We know why the S400 works so well already, it is because of proper engineering and scientific approaches to perfect it. Our waveguide design carries a lot of the answer to that with the directivity matched perfectly with the woofer to make the transition from woofer band to tweeter band practically inaudible at any angle in front of the speaker. Further, we used 2700 measurements all the way around each driver (5402 measurement points in total), to evaluate at each single point around the speaker, to determine if something could be improved further. With the S400 we optimized this to a level that is practically unheard in this price range of speakers, due to state-of-the-art measurement data – and some of the most advanced analysis tools ever made. So – what is yet to be improved in the A500 and A700? A lot!
CONTROLLED DIRECTIVITY AND WHY IT'S IMPORTANT!
So the good news is that most present-day loudspeakers tend to sound pretty good on-axis. What's also true is that there are still many loudspeakers that perform rather poorly as soon as you move off-axis. Since most research suggests that what we hear in-room is estimated to be around 12% direct sound (from your speakers), 44% Early Reflections (from your room), and 44% Sound Power (how the sound loads your room), we strive to create solutions that'll deliver predictable, consistent, and excellent results both on and off axis – regardless of the living space!
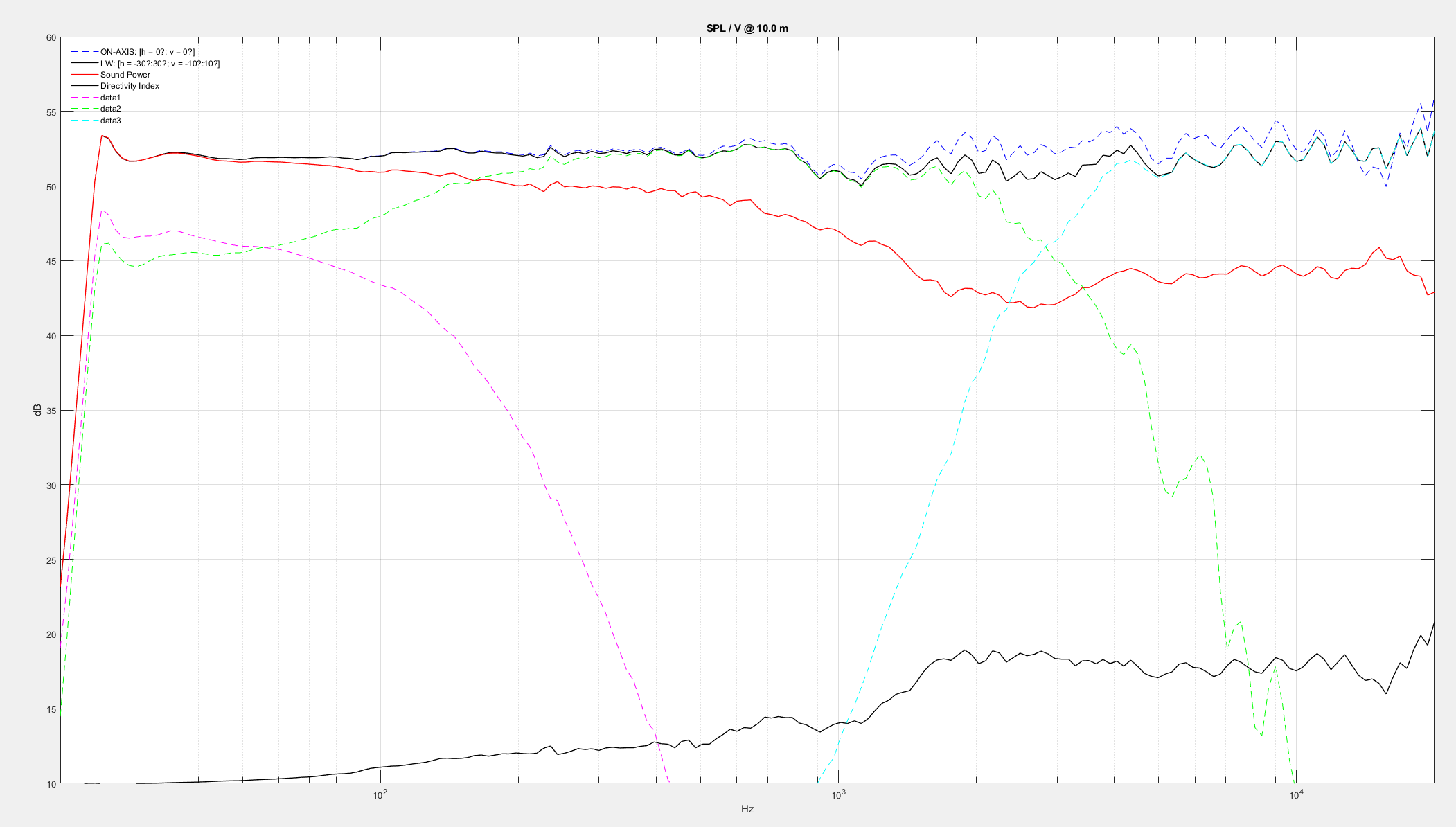
Note how the A500 possesses nearly the same frequency response on-axis as it does in the off-axis.

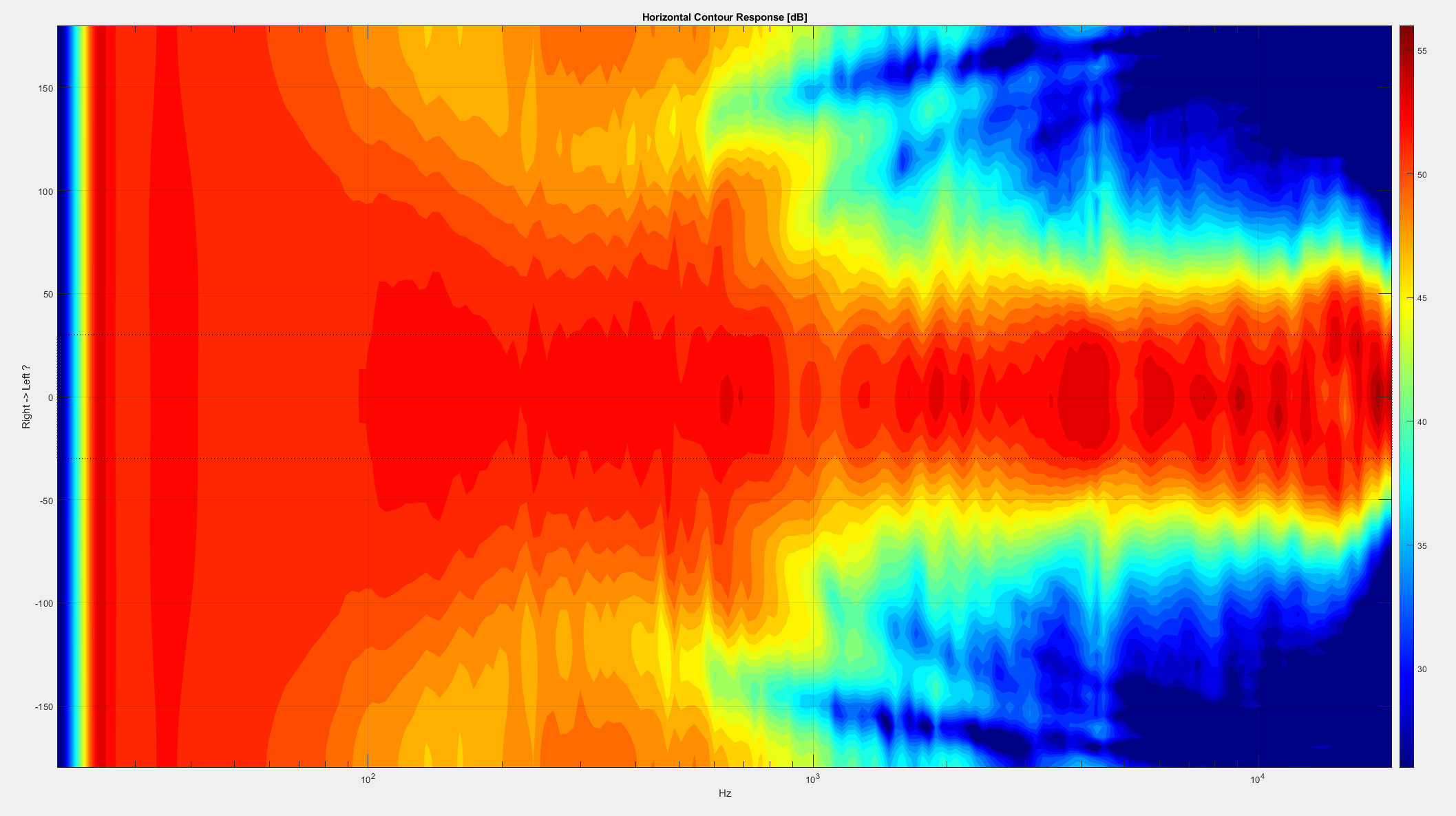
This shows the contour response of A500 (how a speaker spreads the frequencies off-axis). A500 keeps and controls the directivity from 1000 hz and all the way up.
What this translates to is a non-distorted, evenly distributed in-room frequency response that allows the A500's to sound balanced even at extreme angles, which in turn allows the enthusiast to enjoy sundry benefits like improved imaging, a bigger soundstage, and better transparency. This excellent off-axis response will also result in a drastically widened 'sweet spot' and most importantly, a character that will remain steadfast even as you move around your home as the music plays.
We've found that this trait best suits most people’s rooms and lifestyles. Especially those with untreated rooms. The bottom line? The A500 is capable of delivering exceptional in-room performance in any room.
WHATS UP WITH THE DEEP WAVEGUIDE?
So how did we tame the controlled directivity beast? Simple! Through our Constant Directivity Control waveguide! Ok, so maybe the solution isn't that simple. The design itself is the result of a couple very smart people, a number of prototypes, and a super expensive holographic nearfield scanner that we were lucky enough to have access to. This scanner measures 5,402 points around the speaker, this allows us to know exactly how the speaker behave from all possible angles. Thus allowing us to design the perfect waveguide, without suffering any of the major drawbacks! One unique aspect of our waveguide design is that it's designed to match the contour plot of the woofer down to 1000hz, making the tweeter and woofer work as one driver at the crossover point.
Of course, that's only a part of the battle. We also had to phase-align the drivers which is why we have placed the waveguide under the woofer along with leaning the cabinet slightly backwards, all the while making sure that the edge diffractions from the cabinet were reduced by 90%, which is the result of a small tweeter and a very deep waveguide. The result is a sound that's powerful, evenly distributed, and projects freely without 'sticking' to the cabinet. It's just one more important step towards creating a small speaker that sounds full and natural.
WHATS UP WITH OUR SMALL TWEETER?
Ok so first, it's not the size that counts! Still, we get it. Most tweeters measure up to 25-29 mm. Some enthusiasts may feel that our tweeter is a bit... inadequate. We aren't intimidated or ashamed though, because when you get right down to it, there are advantages and disadvantages to tweeters of all sizes.
As an example, larger tweeters tend to be popular because of their power handling and frequency bandwidth, which allows them to be crossed over at lower frequencies. The caveat is that these larger tweeters do not tend to sound as good off-axis and, subjectively speaking, do not sound quite as good (to our ears) as a smaller, well-engineered tweeter. For us, it's all about performance. And when you get right down to it, the 19mm tweeter that we use fits our goals perfectly.
For one, the measurements are about as ideal as we've found. Secondly, the off-axis performance is tremendous. Any of the limitations that would normally come from using this tweeter has been mitigated by our deep waveguide. The end result is exactly what we were looking for. Top end that's effortlessly free of distortion, resulting in a presentation that's clean, detailed, powerful, and perfectly integrated with the rest of the speaker.
PURE DIGITAL SIGNAL PATH - PDS
The A500 and A700 speakers features the best wireless audio technology available. They can support wireless transfer from any WiSA transmitter with a lossless resolution of 24bits/96kHz and with a synchronization error between the speakers of less than 1 sample with the shortest available latency.
This means that we can ensure that the package of bits stored in the mastering studio where the music is recorded can be transported without any loss directly into the heart of the speakers, where our perfectly matched signal path takes over the processing of the data. The benefit of the WiSA technology is, that not only is the signal transfer lossless, it is also controlled in the receiver side, such that the actually received data corresponds 100% with the data sent out. If not, it is sent again. Therefore, we are 100% sure, our speakers are provided with the exact same signal as input to the system. No coloration or degradation. This pure digital signal (PDS) is fed directly into our quad-core DSP, where we do state-of-the-art processing, to optimize the signals for each individual driver to perfection.
DSP CORRECTION – WHY AND HOW?
A DSP itself does not do anything. Used carelessly, a DSP will not help you a lot. But used with proper care and deep analysis, a DSP can bring you very far. But – our DSP is much more than just an advanced crossover network between the audio signal and each of the drivers.
DSP equalization perfected
We have 2700 measurements available for each driver, When run through our own advanced analysis tool, it enables us to distinguish the different acoustic phenomena to the degree that we can also judge which nonlinearities to compensate and precisely how, and which not to touch. We will analyze the effect of our EQ on each of the 2700 measurement points around the speaker, and evaluate the impacts in each point, to judge the acoustic effect of a given correction. With properly set targets, the effect of this EQ approach is an improvement so far unheard. With this technology we can very accurately eliminate system resonances, because they will appear equally bad to all directions, whereas, for example some diffractions will only be seen in specific directions and need different compensation. All of this is done with the aspect in mind to make a speaker as linear as possible, with as little compromise as possible to the off-axis response. Therefore, the fundamentally good acoustic configuration helps us a lot to make as little compromise to either as possible. The bottom line is, the A500 and A700 audio reproduction is a huge step forward in quality.
Automatic ISO 226:2003 Compensation = Low Level Enhancement - LLE
It is well known and documented in research, that the perceived sound balance is dependent on the level at which sound is reproduced. Best example is that with traditional loudspeakers, when listening at quieter levels, there is very little experienced bass and treble reproduction, although at louder level the bass and treble is clearly present. Since we are in control of the entire sound-reproduction chain of the speakers, we can predict the exposed level of sound at the listeners ears, which means we are able to compensate for this effect completely and very accurately. However, we will only do this compensation at low levels (<70dB), where we know most listeners will not perform their critical listening. The outcome from this compensation is a smooth and constantly adapting timbre to the sound, so that it will also sound dynamic and impressive at lower levels, where you can have conversations at the same time during listening. This is a very well engineered feature primarily aimed at professorial use in studios. It allows the mastering engineers to work at lower volumes and still get a precise representation of the music. This allows for much longer work sessions without getting fatigued. For HiFi use, if you often listen at lower volumes this would be a game changer for you!
Bass extension
Another benefit from the use of active systems is the ability to extend the bass reproduction. We tune our systems to play as deep as we can justify given the amount of power available and which the cone/displacement allows us to do, without any distortion to the system. Our DSP will monitor the excursion and health state of each driver, and will adapt the processing dynamically, to ensure the output from each driver is always non-distorted and trimmed to perfection, regardless of the conditions.
Our use of closed cabinets for the A500 and A700 also effectively eliminates the problems occurring in ported systems, where the port at high SPL’s in many cases will become non-linear and unpredictable in terms of output and behavior. Because of our driver monitoring technology, we can extend the performance way beyond what can normally be achieved with a speaker of this size and structure, compared to more traditional designs. Therefore, do not be fooled by the compact sizes of these babies – they will hit way beyond their size.
WHY DRIVERS ON THE BACK OF THE SPEAKER?
During our research for the A500 and A700, we have tried a lot of different configurations in order to obtain the performance we wanted. In the end, we placed some drivers on the back side of the speakers. This has two purposes, from which only one of them is obvious. The obvious reason is that we want to have as much cone area as possible to be able to extend the bass-reproduction as much as possible with as little distortion as possible. The second reason is, that we use the rear drivers with a specially developed algorithm to perfectly align them with the remaining front-firing drivers, without causing any spatial problems to the acoustic dispersion. This allows us to use rear wall reflection to extend our sound image even further than traditional loudspeakers. The result from this is a larger and more precise sound image than you can achieve with traditional front-firing speakers.
MATCHED COMPONENTS TO PERFECTION.
In traditional hi-fi systems, a lot of effort is often spent finding the right combination of components, to meet the optimum performance. In most cases, this is done by ear in private homes - and takes up a lot of time and is quite costly with all the component exchange needed. At Buchardt, we decided to do this component matching for the system by scientific measures and systematic evaluation in our lab, to be sure we made the right choices.
DAC/Amplifier
This active system features two DAC chipsets to control the output channels. It uses the well renowned CS4398 chipset which, when configured properly, performs up to the best chipsets available. The DAC runs on its own regulated power supply to ensure the best possible performance and is linked directly with an amplifier chipset from Texas Instruments for optimum performance, clean reproduction and minimized distortion. The amplifier features a high-speed analog feedback loop, that ensures a bandwidth up to 100kHz and super-low distortion.
Amplifier/drivers
The amplifiers have a specially designed output stage, to perfectly match the driver load with the amplifiers. All of this has been taken into consideration during the acoustic tuning of the speakers – and the outcome is a perfectly matched combination between amplifier and drivers. The power output of each amplifier is 150W per channel, which should be more than enough to exploit the full potential of the system. Given the active nature of the speaker, the total power of the speakers will in real-world compare to much more powerful traditional systems due to no loss in cross-over networks.
Once components are matched, we base all our acoustic evaluations on this chain of components, so that we are always 100% sure what is reproduced. This is how we ensure that what our users will hear is also what we perfected in our lab. The only thing we are still cannot control is the environment the speakers are played in. Therefore, we still require our users to do a final calibration of the system, which will optimize the effects caused by the listening room.
BUCHARDT ROOM CORRECTION
It is well known that the environment in which a speaker is used can change the listening experience significantly. Generally, about listening rooms, the dominating parts are room modes and boundary effects. Our optimization can be done in few minutes – and the data is collected continuously, using the built-in microphone of a smart phone. Please allow us to explain more about them.
Room modes
When music is played in a room, the boundaries of the room will cause sound pressure to be reflected at the boundaries, which is causing a phenomenon often referred to as room modes. These are resonances appearing between walls, ceiling/floor or even in several directions. They will appear at specific frequencies, depending on the room dimension.
These room modes are 3 dimensional issues, meaning that they will appear differently in the room, depending on where you are located. The figure below shows room modes in one dimension of the room e.g. room width. F1 refers to the 1st order standing wave. F2 is a higher frequency mode in the same direction, and the same for f3 and f4 – this is often referred to as the mode order. In theory there are infinite room modes orders, moving upwards in frequency – we will come back to that below.

Figure 1 – room modes between two walls.
As can be seen from figure 1, left side, the f1 has a large area along the walls, where there is high sound pressure level (SPL) and in the middle of the room there is low SPL. For a listener, this particular frequency will appear with a lot of change, when walking from wall to wall in this room.
Another thing to be noted on this basis is, that when the mode order is increased, the deviation in SPL comes close and closer together, making it difficult to distinguish each mode – and only small changes in distance will cause big change in SPL. At this point, the room is entering what is often referred to as the diffuse field of propagation – and the room is no longer dominated by well-defined room modes. It will be one big mixture of standing waves in all directions. Normally this transition happens around 250-300Hz. This transition frequency is often referred to as the Schröder frequency – and is unique for each listening room. It is shown in figure 2 below, how the transition from low modal density happens at Fs and changes into a blur of standing waves – diffusion.

Figure 2 - Fs, Schröder frequency identifies where the transition from modal area to diffusion happen.
Boundary effect
Another room-related problem is the boundary effect. This is what appears when you locate a speaker close to a boundary. From factory – most speakers are tuned to be linear; but this tuning is done in a free-field situation with no boundaries. When a boundary appears behind a speaker, the SPL hitting that boundary will be reflected and thrown back to the listener. This will cause two artefacts: bass-boost and interference

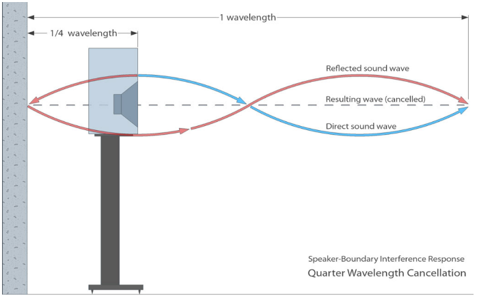
1. Since high frequencies are mainly thrown forward and bass low frequencies are distributed all the way around the loudspeaker, most of the energy from the speaker hitting the rear wall is low frequencies. This means a boundary will cause low frequencies to be reflected and thrown back to the listener, while high frequencies will not. This will cause an overweight of low-frequency content from the speaker as it moves closer to the boundary. More boundaries (corners) will cause this effect even more. This is often referred to as the boundary gain effect (BGE).
2. The other thing that happens, when you move the speaker to a boundary is, that the sound reflected at the boundary will come back to the listener, but now with a latency, compared to the original (non-reflected) signal. This means that at some frequencies they will cancel each other – and at some frequencies they will summarize. The boundary causes some interference which is not easily predicted.
Continuous Soundfield Sampling, CSS
The Buchardt room optimization method takes all the above effects into consideration when performing the calibration. When you walk around with the microphone – covering all positions in the room, we can identify each single room mode – and calculate exactly how to attack it precisely. We can identify the boundary effect caused by the loudspeaker positioning and the interference caused by the boundary. We refer to the method as Continuous Soundfield Sampling (CSS). The benefit of this method is that we have more data available than if you only perform discrete points measurements. With discrete points you have no idea if you are in a minimum or maximum of a room mode – and the risk of making wrong corrections on this basis is high.
Correction only where it makes sense
Since the room acoustics only impacts at frequencies below the Schröder frequency, our compensation will only correct frequencies below that. However, we do capture data all the way up to the high-frequency band. This data is used to align the low-frequency output with the high-frequency output. Since the corrections at low frequencies are quite significant, it can sometimes be difficult to see where the ‘natural’ response of the speaker is – for this we use the high-frequency part for aligning the two bands perfectly with each other.
The correction implementation
The mathematics and analysis tools used to analyze the CSS data is quite heavy. But the CPU of a smartphone (iphones only as of now) will do the job for us. There is no need for cloud-service computers or home PC for this method. We have spent numerous hours optimizing our programming so that the optimizations can be calculated by a smartphone in only a few seconds!! This is thanks to a lot of creative thinking and some ground-breaking research into how an IIR filter can be calculated and ensured to be stable – and still do a perfect fit for our target room EQ response. Once calculated by the phone CPU, the data can be transferred to any DSP and executed with no addition of system latency.
How to do this?
Well, you need our Hub. And as of now, we require that you have access to an Apple Iphone 6S or newer. Remember that you only need to do this once, which means, that as long as you have a friend or family member that owns an Iphone, you can do this. If you move the speakers, you need to redo the correction.
Our room correction has been calibrated to each Iphone model since the Iphone 6S. We have chosen Iphones, because they have very low tolerance regarding their quality control. This means, despite poor quality microphones in the Iphones, we can still trust them to deliver the data we need within a very acceptable tolerance for low frequencies. To bypass the noise from these microphones, we are capturing thousands of measurements doing the one minute the measurement process takes. Yeah, it’s a pretty smart team behind this, right?
To get started, download the Buchardt App from the App store. When you start the room correction via the Buchardt App, you will hear the speakers do pink noise, and see a countdown from 60 seconds. Doing this countdown, walk around with the phone and try to capture as much of the rooms air as possible with large circular motions with phone, but not closer than roughly 1 meter (40”) from the speakers.
When the time is up, you will be shown your room’s frequency response to really get an idea of where your room modes are, within the frequency band. The phone will then use its horsepower to compile all the gathered data to calculate the perfect bass filter. It's directly tailored to your room and the speakers’ placement. You can now switch between "corrected" and "uncorrected" to instantly hear the difference. For most, this will be one of those WOW situations! We are so proud of how well this actually works!
MULTIPLE MASTERTUNINGS!!
Now this is cool and unheard of in the industry! With the flexibility of such powerful DSP, we are in complete control of what we want the speaker to do. This means, that we will provide downloadable master tunings to completely change the fundamentals of the speakers sound design.
So what does this mean?
The standard master tuning the speakers come with, is a 2.5 way design, tuned to 25hz straight with a variable bass tuning. This means, if you play at 100dB, you can't expect two 6” woofers to generate 25hz. The system will then smoothly set the bass tuning higher, so the woofers don’t break. We think this is the best overall tuning for most people.
But what if your needs are different? What if you rarely play loud? Maybe you live in a smaller apartment where SPL is not important to you? Then download a different mastertuning from our website - copy the master tuning file onto a USB key - place the USB key in the USB port on the back of one of the speakers (when it's turned off) - turn it on - remove the USB key and repeat this process on the other speaker. Boom! you now have a speaker that is configured as a 3 way design instead as an example.
What if you want something where deep bass is not important, but SPL is? Maybe you want to use subs with them? Same thing; download a different mastertuning that do just that.
Here, only your imagination is the limit. We are experimenting with Cardioid tuning, semi Cardioid tuning, optimized nearfield tunings for professional studio use and much more. Have any great ideas? Let us know. We wish to make the most flexible speaker in the world. A speaker that we can keep on improving, even long after its release.